Ph.D. positions
Knowledge Graph Reasoning for Semantic Parsing
A fully funded PhD position in NLP is available on a competitive basis at CNRS - Aix-Marseille Université (CNRS - AMU), France.
Applications due by 8 May 2022.
-
Title: Knowledge Graph Reasoning for Semantic Parsing
-
Supervisors: Patrice Bellot (LIS, CNRS - AMU), Mathieu Lafourcade (LIRMM, CNRS - U. de Montpellier) and Jean-Philippe Prost (LPL, CNRS - AMU)
-
Starting date: September 2022 (slightly flexible)
-
How to enquire/apply?
Please send all the required documents (preferably within a single one) in pdf format to Jean-Philippe.Prost@univ-amu.fr
Academic selection criteria
- Required
- Qualification: Master degree (possibly pending), or equivalent (i.e., graduate/postgraduate education)
- French, as it is the target language of the project. Fluency a plus.
- Prior exposure to research, preferably in Natural Language Processing, or Computational Linguistics. Artificial Intelligence or other fields of Computer Science will also be considered
- Strongly expected
- Exposure to knowledge graphs, graph/network theory
- Optional
- Machine Learning, Deep Learning, graph embeddings
Application documents
- Résumé (CV)
- Cover letter, including how you would address the topic (3 pages max)
- University transcripts (at least the last two years of relevant education)
- A piece of academic work authored by the candidate: research paper, essay, report, Masters thesis, etc.
- (optional) recommendation letters
Semantic parsing refers to the language processing task which builds a computational (i.e., “machine-understandable”) representation of the meaning of a text. The task is found in numerous applications in Artificial Intelligence (AI) and Natural Language Processing (NLP) which require an automated step of understanding. Although a number of models and implementations for semantic parsing already exist, there is still room for improvement, and the problem is still being investigated (Zou, 2020).
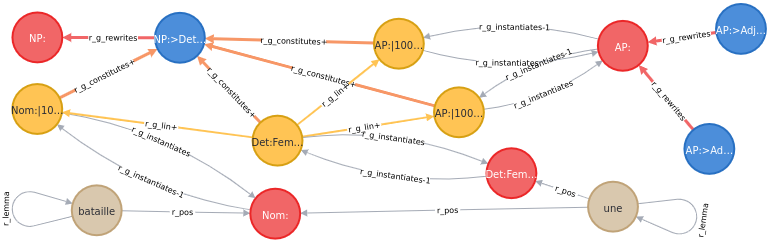
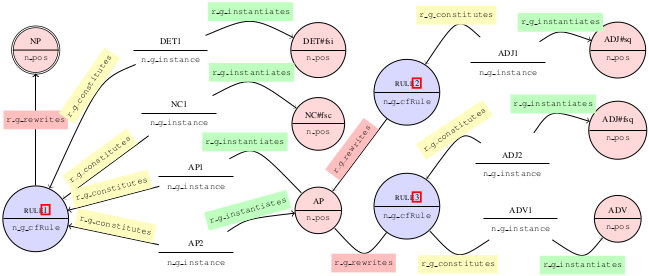
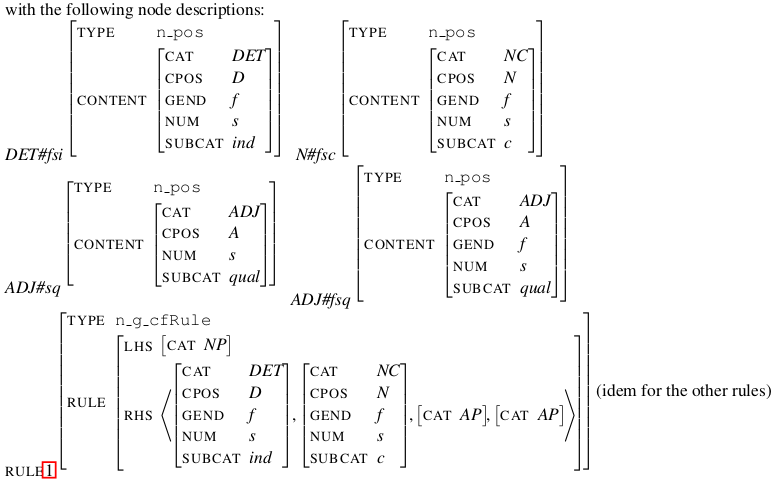
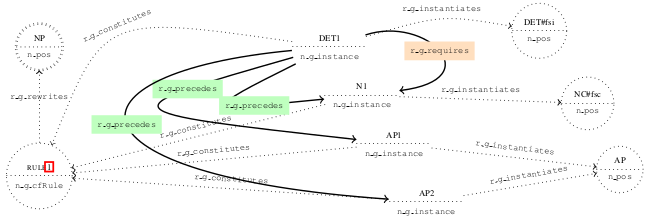
HOLINET is a Knowledge Graph which integrates lexical and semantic knowledge and grammar knowledge. Its originality stands in the integration of heterogeneous information at the interface between Syntax and Semantics. This PhD topic aims to investigate whether such a multi-dimensional integration may take part in graph-theoretic algorithms for the modelling of semantic parsing. A key question lies in the appropriate use of interactions between syntactic and semantic relationships in ways that ease the disambiguation process on the go – as opposed to a sequential use, as in a traditional pipeline architecture.
Could an algorithm for semantic parsing be designed and implemented which would rely simultaneously (a) on the HOLINET grammar layer in order to construct a syntactic structure, and (b) on the lexical and semantic knowledge in order to disambiguate the structure on the fly, during its construction? Can we imagine, for instance on the basis of a PCKY-like chart parser, that the lexical-semantic layer be queried during the parsing process in order to prune branches of the search space?
For example, while parsing “they saw the woman with the telescope”, the following lexical-semantic queries may take part in the process, and be included in the resulting structure:
- Could “they” be agent of “saw”?
[PATTERN : (n_term {name:“they”})-[r_agent]-(n_term {name:“see”})
associated with the dependency (name -agent-> verb)]
- Could we “see” – “by means of (with)” – “something” ?
- Does a “telescope” – “make it possible” – “to see”?
- Could a “woman” – “be accompanied by” – “something”?
- Could a “woman” – “be accompanied by” – a “telescope”?
How to integrate those queries within the parsing process?
How to interpret the answers and automate the subsequent inferences?
The inferred information will be added to the result structure representing the meaning of the input text. It will also help fix cases of ambiguity during the process, e.g. here the case of the Prepositional Phrase (PP) “with the telescope”, which can be attached either to the predicate “saw” or to the Noun Phrase “the girl”.
Additionally, one may also investigate what kind of useful information the language models based on contextual embeddings may introduce in support of the main resource, then compare the approaches. If word embeddings can benefit from external syntactic or semantic knowledge (joint training learning close embeddings for close words and close graph embeddings for close nodes) (Roy & Pan, 2021), the reverse is also true, especially to consider the words out of the vocabulary. In this case, it is the knowledge graph along with the node embeddings that is enriched by new sets of words that must respect the structure and semantic properties of the original graph (Reyazi et al. 2021).
Finally, in order to evaluate the relevance and quality of the result of the semantic parsing process, its ability to address the following linguistic phenomena will be measured (D. Nicolas in “la sémanticlopédie du GDR Sémantique”, following Gillon, 1990, 2004) :
- Polysemic lexical ambiguity (“Pierre sent la rose”)
- Homonymic lexical ambiguity (“Le tigre mange un avocat”)
- Structural ambiguity, e.g. PP attachement (“Je vois la femme avec le télescope")
- Anaphora
- etc.
References
Raisonnement à base de graphe de connaissances pour l’analyse sémantique
L’analyse sémantique fait référence au traitement automatique de la langue qui consiste à construire une représentation (informatique) du sens d’un texte. Ce traitement est au cœur de nombreuses applications d’Intelligence Artificielle (IA) et de Traitement Automatique des Langues (TAL) qui nécessitent une étape de compréhension automatique. Bien qu’un certain nombre de modèles et d’implémentations existent pour l’analyse sémantique, la marge de progression reste importante, et le problème continue donc d’être largement étudié (Zou, 2020).
HOLINET est un graphe de connaissances qui intègre des connaissances lexicales et sémantiques et des connaissances grammaticales. Son originalité tient dans cette intégration d’informations hétérogènes à l’interface entre syntaxe et sémantique. L’objet de cette thèse est de se demander si une telle intégration multidimensionnelle peut être exploitée par des algorithmes de parcours de graphe pour une modélisation du traitement de l’analyse sémantique. Une question centrale concerne l’exploitation judicieuse des interactions entre relations sémantiques et relations syntaxiques de telle sorte qu’elles facilitent la désambiguïsation en cours de processus, et non de façon séquentielle comme c’est le cas dans une architecture classique en pipeline.
Peut-on concevoir et implémenter un algorithme d’analyse sémantique qui s’appuie simultanément sur la grammaire représentée dans HOLINET pour construire une structure syntaxique, et sur les informations lexicales et sémantiques pour désambiguïser cette structure au fur et à mesure de sa construction ?
Sur la base d’un chart parser type PCKY, par exemple, pourrait-on imaginer requêter la couche lexico-sémantique en cours de processus d’analyse afin d’élaguer des branches d’analyse ?
Par exemple, lors de l’analyse de “Je vois la femme avec le télescope", les requêtes lexico-sémantiques suivantes peuvent accompagner le processus, et venir enrichir la représentation finale du sens du texte :
- “je" peut-il “voir” ? [PATTERN : (n_term {nom:“je”})-[r_agent]-(n_term {nom:“voir”}) associé à dépendance (nom -agent-> verbe)]
- Peut-on “voir” – “au moyen de (avec)” – “qq chose” ?
- Un télescope - “permet-il” – de “voir” ?
- Une “femme” – peut-elle “être accompagnée de” – “qq chose” ?
- Une “femme” – peut-elle “être accompagnée de” – “un télescope" ?
Comment automatiser ces requêtes au sein d’un processus d’analyse ?
Comment automatiser l’interprétation des réponses, et les inférences qui en découlent ?
Les informations ainsi inférées pourront être ajoutées à la structure résultat représentant le sens du texte analysé. Elles pourront également, en cours de processus, servir à régler des cas d’ambiguïté, comme ici le cas du groupe prépositionnel “avec le télescope" qui peut être rattaché soit au verbe “voir”, soit au GN “la fille”.
En complément, on pourra s’interroger sur ce que les modèles de langue à plongements (embeddings) contextuels peuvent inclure comme information utile en appui de la ressource, et comparer les approches. Si les plongements lexicaux peuvent bénéficier de connaissances externes syntaxiques ou sémantiques (entraînement joint ciblant des plongements proches pour des mots proches et des nœuds proches) (Roy & Pan, 2021), l’inverse est également vrai, notamment pour considérer les mots hors vocabulaire. Dans ce cas, c’est le graphe de connaissances dont les nœuds sont associés à des plongements qui est enrichi par de nouveaux ensembles de mots qui doivent respecter la structure et les propriétés sémantiques du graphe originel (Reyazi et al. 2021).
Enfin, afin d’évaluer la pertinence et la qualité du résultat du processus d’analyse sémantique, on pourra mesurer son aptitude à résoudre, par exemple, les problèmes et phénomènes linguistiques suivants (D. Nicolas dans la sémanticlopédie du GDR Sémantique, d’après Gillon, 1990, 2004) :
- ambiguïté lexicale polysémique (“Pierre sent la rose”)
- Ambiguïté lexicale homonymique (“Le tigre mange un avocat”)
- Ambiguïté structurale non lexicale, e.g. rattachement de groupe prépositionnel (“Je vois la femme avec le télescope")
- Anaphore
- etc.
References
Roy, A., & Pan, S. (2021, January). Incorporating extra knowledge to enhance word embedding. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence (pp. 4929-4935).
Rezayi, S., Zhao, H., Kim, S., Rossi, R. A., Lipka, N., & Li, S. (2021). EDGE: Enriching knowledge graph embeddings with external text. arXiv preprint arXiv:2104.04909.
Zou, Xiaohan. “A survey on application of knowledge graph.” Journal of Physics: Conference Series. Vol. 1487. No. 1. IOP Publishing, 2020.
Masters internships
Amélioration et déploiement du graphe de connaissances HOLINET – May 2022, M1 (Masters, year #1)
Dans le cadre du projet de développement du graphe de connaissances HOLINET (http://holinet.lpl-aix.fr), nous souhaiterions proposer un stage en linguistique computationnelle pour un étudiant de M1 informatique. L’objet de ce stage serait de contribuer au développement de la ressource principale (disponible sur ORTOLANG : https://hdl.handle.net/11403/holinet-1-0/v1). La construction initiale de cette ressource est décrite dans un article accepté récemment pour présentation orale à LREC 2022.
Accessoirement, ce stage pourrait ouvrir la voie sur une thèse à l’horizon de la rentrée 2023-2024, dont le sujet concernerait le raisonnement sur graphe de connaissances pour l’analyse sémantique du langage naturel.
L’intérêt du graphe HOLINET est de constituer un graphe multi-niveaux, qui intègre une couche lexico-sémantique à travers le réseau JeuxDeMots (https://www.jeuxdemots.org/jdm-accueil.php), et une couche grammaticale. La couche grammaticale est construite initialement sur la base du corpus arboré French Treebank (FTB) annoté en constituance.
Plus précisément, plusieurs objectifs de développement seront proposés au stagiaire, selon son avancement :
- déployer la ressource HOLINET sur un serveur du LPL : configuration de neo4j, installation des données du graphe, développement d’une interface web pour l’interrogation de la base en ligne comme service, développement d’une API d’interrogation hors-ligne.
- améliorer la qualité de l’intégration entre couches lexico-sémantique et grammaticale, en ajoutant au graphe les annotations POS manquantes sur la couche sémantique
- intégration de nouvelles relations sur la couche grammaticale, pour la représentation de relations grammaticales de dépendances, extraites à partir du FTB annoté en dépendances.